Two-phase Commit 经典的2PC 流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 client coordinator slave slave | txn | | | | ----------------->| | | | |-----prepare----->| | | |-----prepare------------------------>| | | | | | |<--------OK-------| | | |<--------OK--------------------------| | | | | | |-----commit ----->| | | |-----commit ------------------------>| | | | | | |<-----OK----------| | | |<-----OK-----------------------------| |<-----reply--------| | |
经典2pc中的Coordinator侧的状态转移:
接受request执行Operation发送prepared message给所有的参与者,initiated
接受到所有participants的positive reply,prepared
发送committ请求给所有的participants, commiting
接受到所有participants的positive reply,committed
Redo & undo log在2pc协议中的作用:
coordinator在Commit Phase发送commit给所有participants之前记录redo log,如果在改动落盘之前coordinator宕机,可以从redo log恢复。
undo log保证了在Prepared Phase中,如果有slave回复不可提交,可用来abort transaction
redo log用来容灾,undo log用来恢复事务执行之前的状态。
Redo & undo log在2pc中写入的时机:
Coordinator:
Prepare Phase, 执行Operation之前记录redolog/undolog
在提交事务之前,记录transaction到redolog
Non-Coordinator:
执行Operation之前记录redolog/undolog
回复positive Response之后将transaction记录到redolog
Classical 2PC的劣势:
阻塞协议,所有的参与者都需要等待coordinator的决策,影响latency
协调者单点失败:如果coordinator失效,协议无法继续。
级联回滚:先到的事务回滚会导致后续的事务级联回滚
参与者单点失败:参与者的失败或者超时,影响latency
大量的网络通信开销:两个阶段的网络开销随着节点数的增多线性增长
DAOS asynchronous 2PC 流程:
client提交txn
coordinator接受,本地执行Operation,发送给其他participants
接受到其他participants的positive Response,标记事务为committable,batch住事务号
batch的事务号达到阈值,发送二阶段的commit rpc
coordinator和slave提交事务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 client coordinator slave slave | txn | | | | ----------------->| | | | |-----prepare----->| | | |-----prepare------------------------>| | | | | | |<--------OK-------| | | |<--------OK--------------------------| |<-------reply------| | | ... time elaps ... ... | | | | | meet batch | | | |--commit batch--->| | | |--commit batch---------------------->| | | | | | |<-----OK----------| | | |<-----OK-----------------------------| | | | |
相对于classical 2PC的改动点
classical 2PC中coordinator在发送prepare之前写redo/undo 日志,A2PC中是发送之后写日志
classical 2PC中coordinator需要再二阶段执行完成后才能回复客户端,A2PC中一阶段完成即可回复
classical 2PC中二阶段的txn都是one by one的处理,A2PC中针对同一Redundancy Group的txns做了batch。
如何处理改动带来的一致性风险
coordinator在一阶段发送rpc后才写日志,假如在写日志之前宕机,可能会有两种场景:
Prepared消息全部发送到了参与者节点
新Coordinator必有这条日志,全部参与者可以提交,Resync协议保证此日志提交
新Coordinator必有这条日志,至少一个参与者abort,Resync协议保证此日志回滚
Prepared消息部分发送到了参与者节点:
新Coordinator有这条日志,由于部分参与者未收到这条Prepare,Resync协议保证此日志回滚
新Coordinator没有这条日志,不会尝试abort或者commit,客户端Timeout,对此日志在新的Coordinator上发起重试。
如何解决batch机制引入的inconsistency 由于batch机制,Coordinator状态为committable的状态的事务,在participants端可能是prepared的状态,participants端的读写请求如何处理?
写请求:统一由leader端处理
读请求:通过redirect到leader端处理或者依赖于refresh流程同步后再处理
新的Coordinator如何产生
通过伪哈希算法,在剩余的存活参与者中选出,因为参与者携带了未决事务的信息。
不能选择Fallback节点作为新的Coordinator,因为FallBack节点没有事务信息,无法执行Resync流程。
旧的Coordinator如何处理
暂时下线:在重新上线后,依赖rebuild协议同步事务信息
永久下线:在FallBack上rebuild事务信息
Resync principals
存活的节点,有任何节点针对此txn提交为abort或者没有voted log,则此txn回滚
失联的节点abort了当前事务且至少和一个存活节点确认了abort信息,此txn回滚
存活的节点对txn1标记为prepared,失联的leader对txn1标记为abort,txn1可以提交。
流程
client发送txn
leader接受,replicate,将log持久化
slave接受,将log持久化,处理txn
slave回复,leader接受
leader汇总,根据汇总结果abort或者commit
leader回复client
leader cache txn,等到batch满发送给slaves
slave做相应的处理。
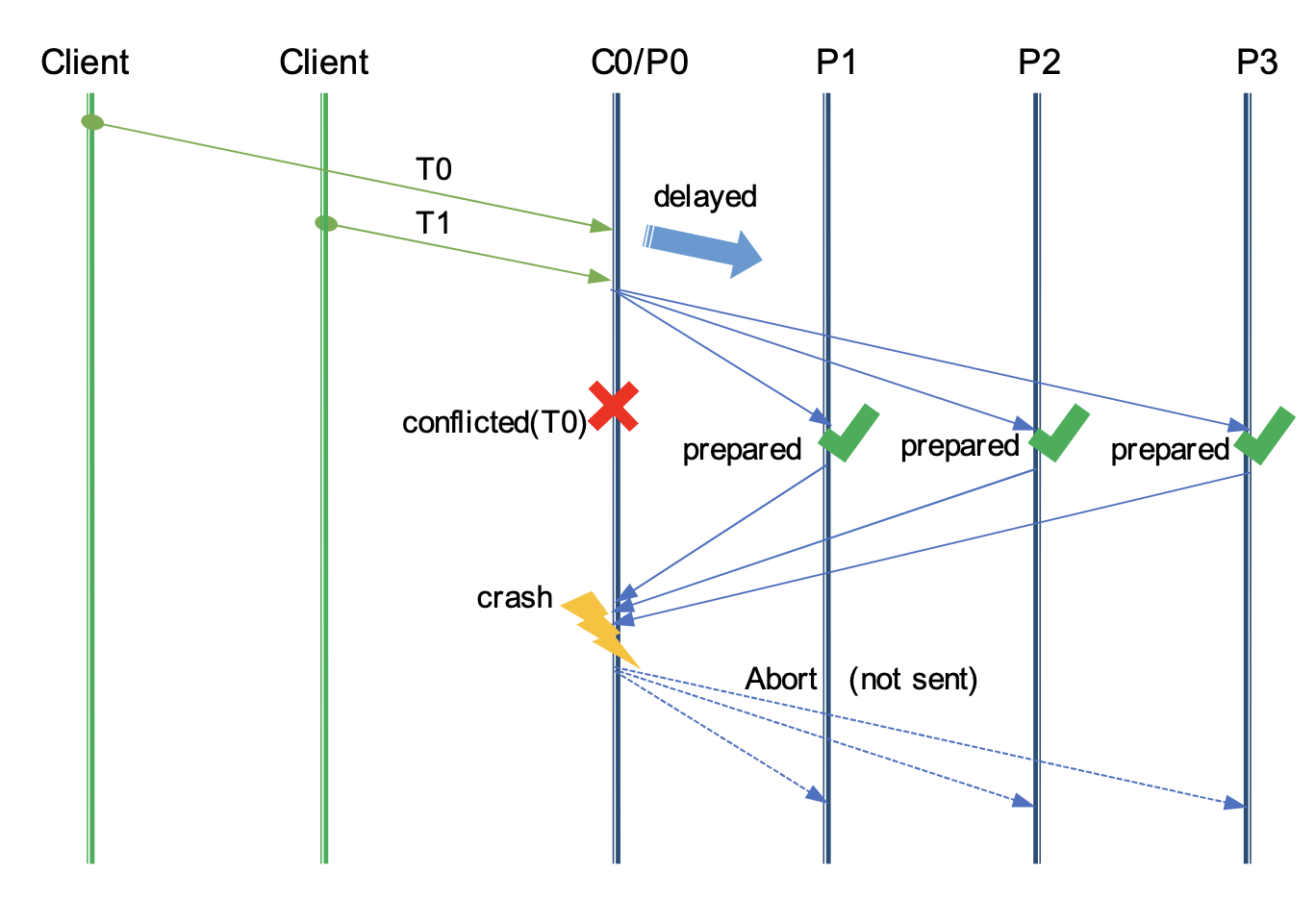
极端例子
T0到达client比T1早,T0和T1之间是冲突关系
T0在Coordinator执行成功,T1在Coordinator执行失败
T1的Prepare rpc已经先于T0到达了所有的参与者,且所有参阅者回复positive
协调者在收到T1的回复之前crash,无法发送abort T1
在Resync流程中,T1被commit,T0超时,因为crash之前并没有回复客户端,因此不影响一致性
Refresh 流程:
获取需要Refresh的dtx列表
遍历每个dtx
查找dtx leader
如果自己是leader,跳过当前dtx的检查
初始化
向leader发送RPC进行事务状态同步
根据同步的事务结果做相应的处理
Classical 2PC & asynchronous 2PC对比: asynchronous 2PC解决了哪些问题:
Prepare阶段结束后就响应客户端,缓解了阻塞问题,至少节省了一个RTT的时间
Prepare阶段,不写日志就发rpc,至少节省了一次落盘的时间
参与者失败,通过SWIM协议在有限时间内发现并启用fallback,协调者失败,通过resync决策事务状态,一定程度上解决了了协调者和参与者的失败问题
Commit阶段通过batch成组提交,减小网络通信的开销
级联回滚依然存在
asynchronous 2PC可能带来那些问题:
asynchronous 2PC不是单独可用的协议,需要SWIM协议配合
引入resync的过程,增加了复杂性
batch提交引入了额外的复杂性,传统的2PC中,各节点的状态一致,任何节点都可以处理读写请求。在a2PC中,leader会将已经提交的事务的二阶段batch,因此slave节点上的事务状态仍然是Prepared,需要同步信息或者只由leader处理。
代码 client端: 伪代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 daos_handle_t tx = DAOS_TX_NONE; int rc; /* allocate transaction */ rc = daos_tx_open(dfs->coh, &th, 0, NULL); if (rc) ... restart: /* execute operations under the same transaction */ rc = daos_obj_fetch(..., th); ... rc = daos_obj_update(..., th); ... if (rc) { rc = daos_tx_abort(th, NULL); /* either goto restart or exit */ } rc = daos_tx_commit(th, NULL); if (rc) { if (rc == -DER_TX_RESTART) { /* conflict with another transaction, try again */ rc = daos_tx_restart(th, NULL); goto restart; } ... } /* free up all the resources allocated for the transaction */ rc = daos_tx_close(th, NULL);
关键调用点 构造task 1 2 int daos_tx_commit(daos_handle_t th, daos_event_t *ev)
检查txn的状态是否满足提交条件 1 2 int dc_tx_commit(tse_task_t *task)
发送rpc 1 2 3 4 5 6 7 // 检查pool_map_version是够匹配 // dc_tx_commit_prepare,比较复杂,取第一个target作为leader // 注册回调dc_tx_commit_cb // 修改事务状态为TX_COMMITTING // 构造rpc并发送rpc static int dc_tx_commit_trigger(tse_task_t *task, struct dc_tx *tx, daos_tx_commit_t *args)
Server端 关键调用点 检查冲突,分配内存,为每个子txn分配执行函数 1 2 void ds_obj_cpd_handler(crt_rpc_t *rpc)
执行Server端的leader操作 1 2 3 4 // 执行Server端的leader操作,设置内存栅栏 // 为每个txn的每个tgt执行obj_obj_dtx_leader static void ds_obj_dtx_leader_ult(void *arg)
在txn的每个tgt上执行Operation 1 2 static void ds_obj_dtx_leader(struct daos_cpd_args *dca)
分batch执行 1 2 3 4 int dtx_leader_exec_ops(struct dtx_leader_handle *dlh, dtx_sub_func_t func, dtx_agg_cb_t agg_cb, int allow_failure, void *func_arg)
leader上的每个tgt执行到的函数 1 2 3 static int obj_obj_dtx_leader(struct dtx_leader_handle *dlh, void *arg, int idx, dtx_sub_comp_cb_t comp_cb)
1 2 3 4 static int ds_cpd_handle_one_wrap(crt_rpc_t *rpc, struct daos_cpd_sub_head *dcsh, struct daos_cpd_disp_ent *dcde, struct daos_cpd_sub_req *dcsrs, struct obj_io_context *ioc, struct dtx_handle *dth)
leader 和 slave上都会执行到的读写接口 1 2 3 4 5 6 7 8 9 10 // leader 和 slave上都会执行到的操作 // 执行时机的写入操作,更新ts,此函数比较复杂 static int ds_cpd_handle_one(crt_rpc_t *rpc, struct daos_cpd_sub_head *dcsh, struct daos_cpd_disp_ent *dcde, struct daos_cpd_sub_req *dcsrs, struct obj_io_context *ioc, struct dtx_handle *dth) /* Locally process the operations belong to one DTX. * Common logic, shared by both leader and non-leader. */
2nd phase 1 2 int dtx_leader_end(struct dtx_leader_handle *dlh, struct ds_cont_hdl *coh, int result)
Resync关键调用点 入口 1 2 3 // 构造Resync的txn列表 int dtx_resync(daos_handle_t po_hdl, uuid_t po_uuid, uuid_t co_uuid, uint32_t ver, bool block)
one by one的检查 1 2 3 4 5 // 在这个function中one by one的检查 // 如果返回的结果是DSHR_NEED_COMMIT,batch住txn,等待提交 // 否则不会提交 static int dtx_status_handle(struct dtx_resync_args *dra)
检查某一个entry 1 2 3 4 5 // 检查某一个entry // 返回commit,则返给上层提交 int dtx_status_handle_one(struct ds_cont_child *cont, struct dtx_entry *dte, daos_epoch_t epoch, int *tgt_array, int *err)
发送rpc同步Commit信息 1 2 int dtx_check(struct ds_cont_child *cont, struct dtx_entry *dte, daos_epoch_t epoch)
DTX Check的逻辑 1 2 3 static void dtx_handler(crt_rpc_t *rpc)
rpc处理 1 2 static int dtx_rpc_internal(struct dtx_common_args *dca)
rpc发送 1 2 static int dtx_req_list_send(struct dtx_common_args *dca, daos_epoch_t epoch, int len)
回调汇总 1 2 3 4 // 所有peers检查后的结果汇总回调 // Resync principals static void dtx_req_list_cb(void **args)
Refresh关键调用点 server A 触发refresh 1 2 3 4 5 int dtx_refresh_internal(struct ds_cont_child *cont, int *check_count, d_list_t *check_list, d_list_t *cmt_list, d_list_t *abt_list, d_list_t *act_list, bool failout) // 删选出leader不是当前节点的dtx列表
准备rpc并发送给Leader 1 2 3 4 // 为leader不是当前节点的所有dtx发送rpc rc = dtx_rpc_prep(cont, &head, NULL, len, DTX_REFRESH, 0, cmt_list, abt_list, act_list, &dca); rc = dtx_rpc_post(&dca, rc);
处理leader不是当前节点的所有dtx的检查结果 1 2 3 d_list_for_each_entry_safe(dsp, tmp, cmt_list, dsp_link) // 处理可提交的事务 d_list_for_each_entry_safe(dsp, tmp, abt_list, dsp_link) // 处理可bort的事务 d_list_for_each_entry_safe(dsp, tmp, act_list, dsp_link) // 处理uncertain和inprogress的事务
遍历处理leader即为当前节点的每个dtx 1 d_list_for_each_entry_safe(dsp, tmp, &self, dsp_link)
为每个dtx做检查 1 2 3 4 int dtx_status_handle_one(struct ds_cont_child *cont, struct dtx_entry *dte, daos_epoch_t epoch, int *tgt_array, int *err) // 根据检查返回的结果做相应的处理
Leader端 处理refresh rpc 1 2 3 static void dtx_handler(crt_rpc_t *rpc) case DTX_REFRESH分支
调用vos来做检查 1 2 3 4 int vos_dtx_check(daos_handle_t coh, struct dtx_id *dti, daos_epoch_t *epoch, uint32_t *pm_ver, struct dtx_memberships **mbs, struct dtx_cos_key *dck, bool for_refresh)
根据返回结果逐个处理dtx
Q&A
rebuild结束后才能开始Resync吗?
论文中没有明确提及。
一个事务中会有多个Operation,如果是replication协议,那么为什么≤还要引入两阶段提交?
Daos中的raft只用在pool或者Container service的主从之间同步状态,不用于数据的replication。
classical 2PC中Prepared的语义和a2PC中语义的区别
classical 2PC中,coordinator接收到所有其他participants节点的positive reply后标记事务状态为Prepared
a2PC中,coordinator或者其他节点,只要执行完了事务的operations,即可认为是Prepared状态。
DTE_ORPHAN是如何处理的?