// leader 和 slave上都会执行到的操作 // 执行时机的写入操作,更新ts,此函数比较复杂 static int ds_cpd_handle_one(crt_rpc_t *rpc, struct daos_cpd_sub_head *dcsh, struct daos_cpd_disp_ent *dcde, struct daos_cpd_sub_req *dcsrs, struct obj_io_context *ioc, struct dtx_handle *dth) /* Locally process the operations belong to one DTX. * Common logic, shared by both leader and non-leader. */
2nd phase
1 2
int dtx_leader_end(struct dtx_leader_handle *dlh, struct ds_cont_hdl *coh, int result)
begin T2 R(X) |------------------------------|------------------------------------------ case 1 begin T2 R(X) |-----------------------------|----------------------------- case 2 begin T1 W(X) |--------------|------------------------------------------------------ begin T2 R(X) |--------------|-------------------------- case 3
begin T2 W(X) |------------------------------|------------------------------------------ case 1 begin T2 W(X) |-----------------------------|----------------------------- case 2 begin T1 R(X) |--------------|------------------------------------------------------
begin T2 W(X) |------------------------------|------------------------------------------ case 1 begin T2 W(X) |-----------------------------|----------------------------- case 2 begin T1 W(X) |--------------|------------------------------------------------------
A read at epoch e follows these rules: (对应于写读冲突中的三个case)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// Epoch uncertainty check if e is uncertain // 写读冲突,读事务的读操作的开始晚于其他事务的写操作(读事务的读操作一定是在e_orig + epsilon之后吗?) if there is any overlapping, unaborted write in(e, e_orig + epsilon] reject // 回滚读 (case1&case2) find the highest overlapping, unaborted write in [0, e] //写读冲突,读事务的开始时间晚于其他写事务的写操作事件 if the write is not committed // 等待 wait for the write to commit orabort if aborted retry the find skipping this write // 如果其他写事务abort,此读事务retry (case3) // Read timestamp update for level i from container to the read's level lv update i.high // 更新TimeStamp Cache update lv.low
// Epoch uncertainty check if e is uncertain // 写写冲突,后写abort(认为当前事务的写在e_orig + epsilon时间之后) if there is any overlapping, unaborted write in(e, e_orig + epsilon] reject // Read timestamp check, 检查读写冲突,读在前写在后 for level i from container to one level above the write // 读写冲突,如果父节点的low小于当前事务的开始时间,意味着父节点下的所有子节点都在low这个时间点被读过,则可以推导出write的目 // 标value在low时间被读取过,当前事务的开始时间早于value的读操作时间,则当前事务需要abort // (i.low == e) && (other reader @ i.low) --> 检查是否是同一个txn中的操作,如果是同一个txn的读写,则不需要abort // 这些父节点的检查可能是想快速判断出是够有冲突,不必递归到目标项上做检查 if (i.low > e) || ((i.low == e) && (other reader @ i.low)) reject // 检查目标项,读写冲突,abort写 if (i.high > e) || ((i.high == e) && (other reader @ i.high)) reject // 此处的overlapping检查逻辑暂不明确作用,好像也是在检查写写冲突 // 上面的写写冲突检查区间并没有覆盖到e这个点,是个左开右闭区间,不清楚为什么要分开检测 find if there is any overlapping write at e if found and from a different transaction reject
if (se->se_etype > write_level) returnfalse; /** Check is redundant */
/** NB: If there is a negative entry, we should also check it. Otherwise, we can miss * timestamp updates associated with conditional operations where the tree exists but * we don't load it ,不太明白这边的negative是什么意思? */ // 检查目标value父节点 // for level i from container to one level above the write if (se->se_etype < write_level) { /* check the low time */ conflict = vos_ts_check_conflict(entry->te_ts.tp_ts_rl, &entry->te_ts.tp_tx_rl, write_time, &ts_set->ts_tx_id);
case1: <-----------X----------------|----------------o-----------------o------------------> current bound U1 U2 case2: <-----------o----------------v----------------|-----------------o------------------> U1 current bound U2 case3: <-----------o----------------x----------------o-----------------|------------------> U1 current U2 bound case4: <-----------o----------------o----------------v-----------------|------------------> U1 U2 current bound
/** Do an uncertainty check on the entry. Return true if there * is a write within the epoch uncertainty bound or if it * can't be determined that the epoch is safe (e.g. a cache miss). * * There are the following cases for an uncertainty check * 1. The access timestamp is earlier than both. In such * case, we have a cache miss and can't determine whether * there is uncertainty so we must reject the access. * 2. The access is later than the first and the bound is * less than or equal to the high time. No conflict in * this case because the write is outside the undertainty * bound. * 3. The access is later than the first but the bound is * greater than the high timestamp. We must reject the * access because there is an uncertain write. * 4. The access is later than both timestamps. No conflict * in this case. * * \param[in] ts_set The timestamp set * \param[in] epoch The epoch of the update * \param[in] bound The uncertainty bound */ staticinlinebool vos_ts_wcheck(struct vos_ts_set *ts_set, daos_epoch_t epoch, daos_epoch_t bound) { structvos_wts_cache *wcache; structvos_ts_set_entry *se; uint32_t high_idx; daos_epoch_t high; daos_epoch_t second;
se = &ts_set->ts_entries[ts_set->ts_init_count - 1];
if (se->se_entry == NULL) returnfalse;
wcache = &se->se_entry->te_w_cache; high_idx = wcache->wc_w_high; high = wcache->wc_ts_w[high_idx]; // 事务的开始时间晚于任何其他事务的写时间,不产生任何冲突 // 写读冲突中的case3,读事务的开始时间晚于其他事务的写操作时间,需要返回等待 // 写写冲突中,写事务的开始时间晚于其他事务的写操作时间,不冲突 if (epoch >= high) /* Case #4, the access is newer than any write */ returnfalse;
second = wcache->wc_ts_w[1 - high_idx]; // 事务的开始时间小于其他事务写此value的Tlow,当前事务的写应该被abort // 写读冲突中,读事务的开始时间早于写事务的写操作时间,读操作需要被abort,写读冲突中的case1和case2属于此类 // 写写冲突中,写事务的开始时间早于其他写事务的写操作时间,后写的需要被abort,写写冲突中的case1和case2属于此种 if (epoch < second) /* Case #1, Cache miss, not enough history */ returntrue;
/* We know at this point that second <= epoch so we need to determine * only if the high time is inside the uncertainty bound. */ if (bound >= high) /* Case #3, Uncertain write conflict */ returntrue;
In order to detect epoch uncertainty violations, VOS also maintains a pair of write timestamps for each container, object, dkey, and akey. Logically, the timestamps represent the latest two updates to either the entity itself or to an entity in a subtree. At least two timestamps are required to avoid assuming uncertainty if there are any later updates. The figure below shows the need for at least two timestamps. With a single timestamp only, the first, second, and third cases would be indistinguishable and would be rejected as uncertain.
NB: If there is a negative entry, we should also check it. Otherwise, we can miss timestamp updates associated with conditional operations where the tree exists but we don’t load it
其他参考:
CockroachDB中关于TimeStamp Cache的描述:
Read-Write Conflicts – Read Timestamp Cache
On any read operation, the timestamp of that read operation is recorded in a node-local timestamp cache. This cache will return the most recent timestamp at which the key was read.
All write operations consult the timestamp cache for the key they are writing; if the returned timestamp is greater than the operation timestamp, this indicates a RW conflict with a later timestamp. To disallow this, the operation (and its transaction) must be aborted and restarted with a later timestamp.
The timestamp cache is an interval cache, meaning that its keys are actually key ranges. If a read operation is actually a predicate operating over a range of keys (such as a scan), then the entire scanned key range is written to the timestamp cache. This prevents RW conflicts where the key being written was not present during the scan operation.
The timestamp cache is a size-limited, in-memory LRU (least recently used) data structure, with the oldest timestamps being evicted when the size limit is reached. To deal with keys not in the cache, we also maintain a “low water mark”, which is equivalent to the earliest read timestamp of any key that is present in the cache. If a write operation writes to a key not present in the cache, the “low water mark” is returned instead.
Write-Write Conflicts – Can only write the most recent version of a key
If a write operation attempts to write to a key, but that key already has a version with a later timestamp than the operation itself, allowing the operation would create a WW conflict with the later transaction. To ensure serializability, the operation (and its transaction) must be aborted and restarted with a later timestamp.
By choosing a timestamp-based ordering, and rejecting all conflicts which disagree with that ordering, CockroachDB’s Serializable Snapshot guarantees a serializable schedule.
Timestamp cache
The timestamp cache tracks the highest timestamp (i.e., most recent) for any read operation that a given range has served.
Each write operation in a BatchRequest checks its own timestamp versus the timestamp cache to ensure that the write operation has a higher timestamp; this guarantees that history is never rewritten and you can trust that reads always served the most recent data. It’s one of the crucial mechanisms CockroachDB uses to ensure serializability. If a write operation fails this check, it must be restarted at a timestamp higher than the timestamp cache’s value.
Safety. They never return incorrect results under all non- Byzantine conditions.
Liveness. They are fully functional as long as any majority of the servers are alive and can communicate with each other and with clients. We call this group of servers healthy.
Safety property由Leader Completeness Property 保证: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
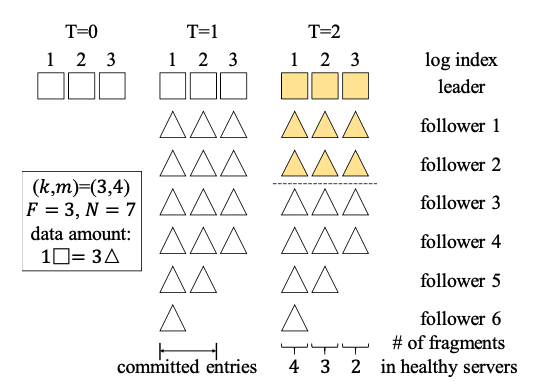
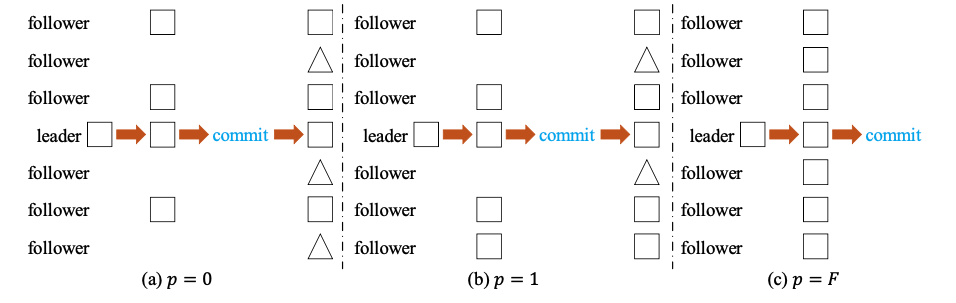
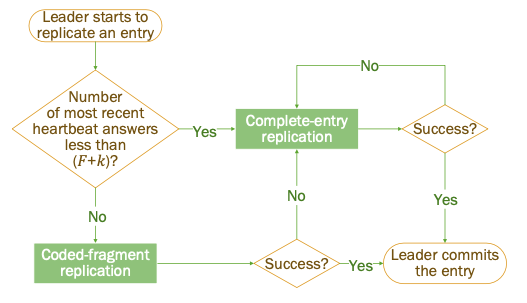
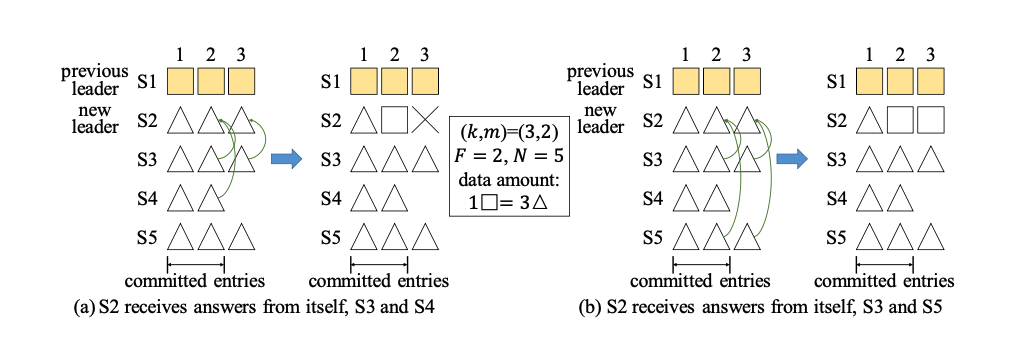
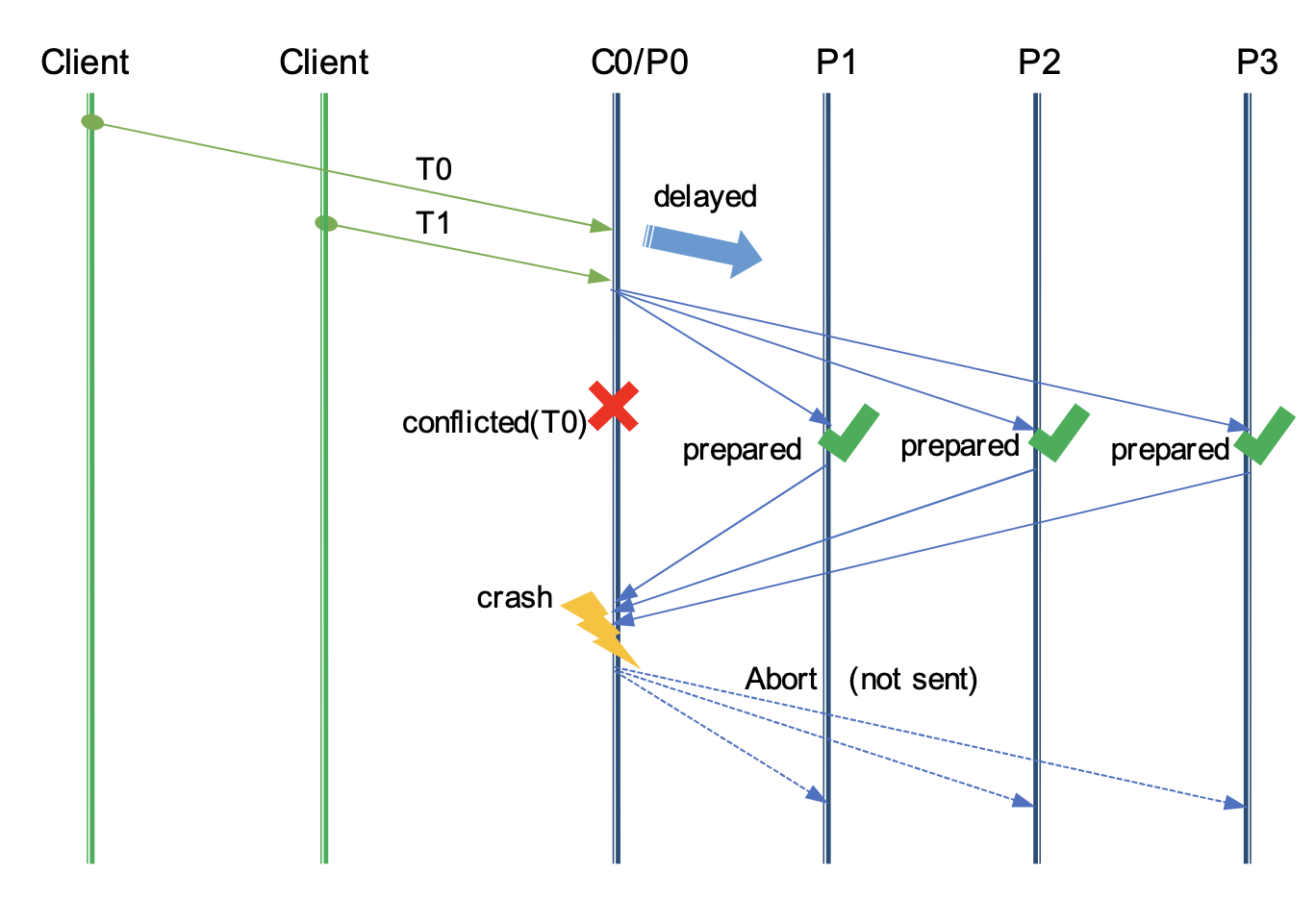
设 A = (F + k),B = (F + 1) A + B = F + k + F + 1 = 2F + 1 + K 因为 2F + 1 = N 所以 A + B - N = 2F + 1 - N + K = k (1) 根据 A ∪ B = A + B − A ∩ B,因此 A ∩ B = A + B - A ∪ B (2) 由于 A 和 B都属于raft组的majority,因此 A ∪ B <= N 所以 A + B - N < A + B - A ∪ B, 带入 (1)和(2),的 k < A ∩ B
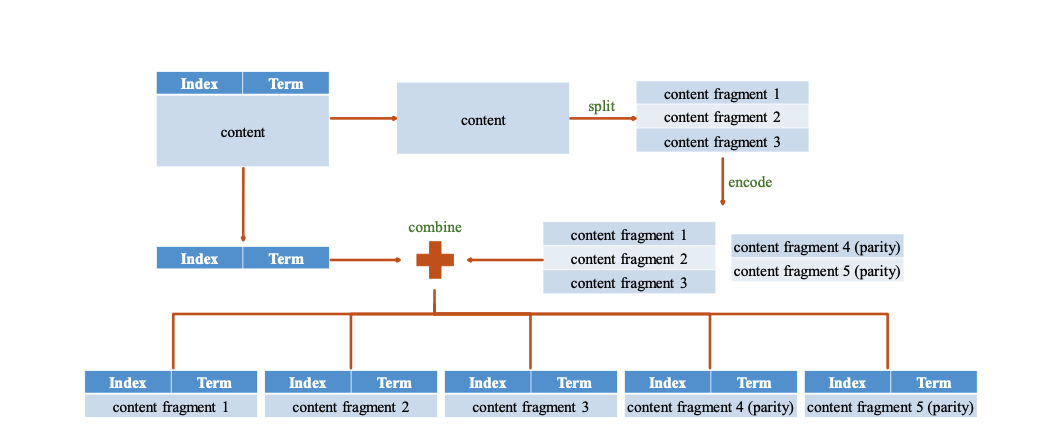
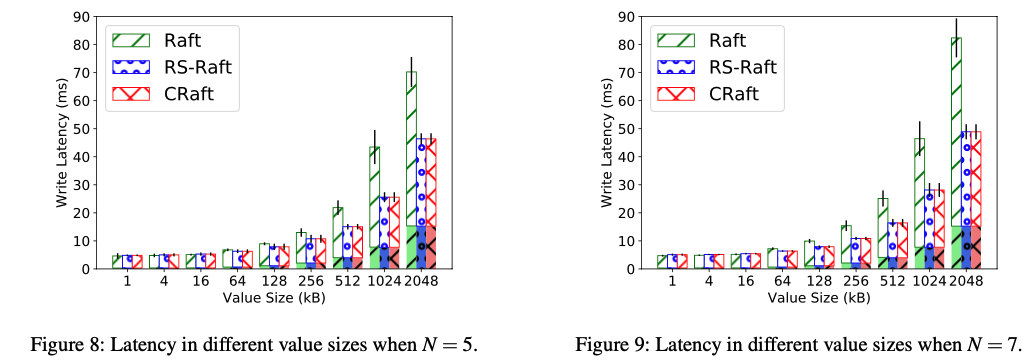
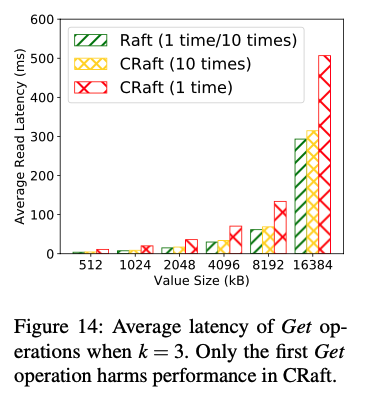
在value size比较小的时候,几乎没有性能区别,在value size比较大的时候,因为CRaft只做coded-fragment分发,因此性能优势明显。(they reduce 20%–45% of latency compared to Raft when N = 5, and 20%–60.8% when N = 7.)
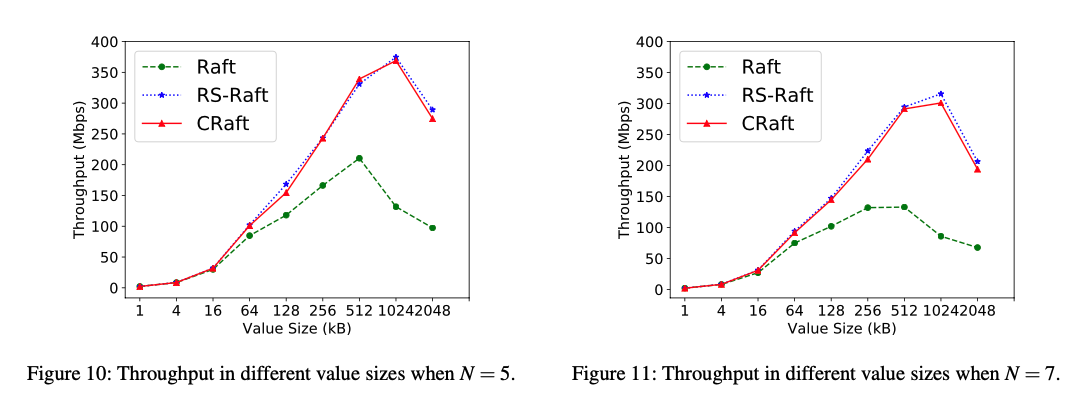
Throughput
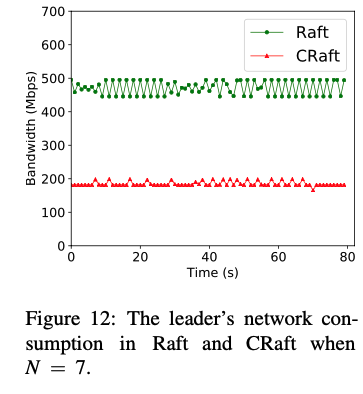
value size比较大的时候,对于带宽的提升明显,大到临界点时,总带宽会降低,因为遇到了网络拥塞问题(CRaft and RS-Raft can have a 180% improvement on write throughput when N = 5 and 250% when N = 7. Also, the throughput peaks of CRaft and RS-Raft both appear much later than Raft’s. )
gdb + 可执行二进制程序 r + 参数列表 b + 断点行数 bt 显示堆栈信息 print 打印表达式值 continue 在一个断点之后继续执行 list 列出源码的一部分 next 在停止之后单步执行 set 设置变量的值 step 进入函数调用 watch 监视一个函数的值 rwatch 监视变量被读暂停程序 awatch 监视变量被读写暂停程序 disable 消除断点 display 在断点停止的地方显示表达式的值 enable 允许断点 finish 继续执行直到函数返回 ignore 忽略断点的次数 info 查看信息 load 动态加载程序到调试器 whatis显示变量的值和类型 ptype 显示变量的类型 return 强制从当前函数返回 make 不退出gdb即可重新产生可执行文件 shel 不退出gdb即可执行linux shell命令 help quit
常用参数
参数
解析
-e
指定可执行文件名
-c
指定coredump文件
-d
指定目录加入到源文件搜索路径
–cd
指定目录作为路径运行gdb
-s
指定文件读取符号表
-p
指定attach进程
调试进程
1 2
gdb -p 进程名 gdb attach 进程名
调试线程
1 2
info thread //列出已允许的进程下的线程 thread 线程号 //切换到线程
查看相关信息
1 2 3 4 5
(gdb) info thread //列出线程 (gdb) info register //列出寄存器 (gdb) info frame //列出栈帧 (gdb) info files //列出当前文件 (gdb) info share //列出当前共享库
指定程序允许参数
1 2
set args 1 2 3 4 show args
其他参数
1 2 3 4 5 6 7 8 9
path 设定程序的允许路径 show path set environment K=v 设置环境变量 show environment 查看环境变量 show language 查看语言环境 info frame 查看函数的程序语言 info source 查看当前文件的程序语言 info breakpoints 显示所有断点 info terminal 显示程序用到的终端模式
(gdb) print num (gdb) p num (gdb) print file::variable (gdb) print function::variable (gdb) p *array@len $1 = {2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40} #静态数组直接print + 数组名就可以打印内容
源代码显示
1 2 3 4 5 6 7 8 9 10
命令 解析 list n 显示程序第n行的周围的源程序。 list function 显示函数名为function的函数的源程序。 list +n 显示当前行n后面的源程序。 list -n 显示当前行n前面的源程序。 set listsize 设置一次显示源代码的行数。 show listsize 查看当前listsize的设置。 # 查看源代码的内存地址 (gdb) info line tst.c:func Line 5 of "tst.c" starts at address 0x8048456 and ends at 0x804845d .
查看内存地址保存的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
你可以使用examine命令(简写是x)来查看内存地址中的值。x命令的语法如下所示:
(gdb) x/nfu addr 1 n 是一个正整数,表示显示内存的长度,也就是说从当前地址向后显示几个地址的内容。 f 表示显示的格式,参见上面。如果地址所指的是字符串,那么格式可以是s,如果地十是 指令地址,那么格式可以是i。 u 表示从当前地址往后请求的字节数,如果不指定的话,GDB默认是4个bytes。u参数可 以用下面的字符来代替,b表示单字节,h表示双字节,w表示四字节,g表示八字节。当 我们指定了字节长度后,GDB会从指内存定的内存地址开始,读写指定字节,并把其当作 一个值取出来。 addr表示一个内存地址。 n/f/u三个参数可以一起使用。例如:
frame 或 f 会打印出这些信息:栈的层编号,当前的函数名,函数参数值,函数所在文件及行号,函数执行到的语句。 查看当前栈帧中存储的信息
(gdb) info frame Stack level 0, frame at 0x7ffc1da10e80: rip = 0x7f800008b4e3 in __epoll_wait_nocancel; saved rip = 0x5560eac8b902 called by frame at 0x7ffc1da11280 Arglist at 0x7ffc1da10e70, args: Locals at 0x7ffc1da10e70, Previous frame's sp is 0x7ffc1da10e80 Saved registers: rip at 0x7ffc1da10e78
iod.iod_nr = 1; /** has to be 1 for single value */ iod.iod_size = BUFLEN; /** size of the single value */ iod.iod_recxs = NULL; /** recx is ignored for single value */ iod.iod_type = DAOS_IOD_SINGLE; /** value type of the akey */
Create the array object with cell size 1 (byte array) and 1m chunk size (similar to stripe size in Lustre). Both are configurable by the user of course :
media = vos_media_select(vos_cont2pool(ioc->ic_cont),
iod->iod_type, size); //决定往哪个media上写,0 –> scm
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* * A simple media selection policy embedded in VOS, which select media by * akey type and record size. */ staticinlineuint16_t vos_media_select(struct vos_pool *pool, daos_iod_type_t type, daos_size_t size) { if (pool->vp_vea_info == NULL) return DAOS_MEDIA_SCM;
/* * Check if the dedup data is identical to the RDMA data in a temporal * allocated DRAM extent, if memcmp fails, allocate a new SCM extent and * update it's address in VOS tree, otherwise, keep using the original * dedup data address in VOS tree. */
/** * Load the subtree roots embedded in the parent tree record. * * akey tree : all akeys under the same dkey * recx tree : all record extents under the same akey, this function will * load both btree and evtree root. */ /* NB: In order to avoid complexities of passing parameters to the * multi-nested tree, tree operations are not nested, instead: * * - In the case of fetch, we load the subtree root stored in the * parent tree leaf. * - In the case of update/insert, we call dbtree_update() which may * create the root for the subtree, or just return it if it's already * there. */
media = vos_media_select(vos_cont2pool(ioc->ic_cont),
iod->iod_type, size); //决定往哪个media上写,0 –> scm
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* * A simple media selection policy embedded in VOS, which select media by * akey type and record size. */ staticinlineuint16_t vos_media_select(struct vos_pool *pool, daos_iod_type_t type, daos_size_t size) { if (pool->vp_vea_info == NULL) return DAOS_MEDIA_SCM;
/* * Check if the dedup data is identical to the RDMA data in a temporal * allocated DRAM extent, if memcmp fails, allocate a new SCM extent and * update it's address in VOS tree, otherwise, keep using the original * dedup data address in VOS tree. */
/** * Load the subtree roots embedded in the parent tree record. * * akey tree : all akeys under the same dkey * recx tree : all record extents under the same akey, this function will * load both btree and evtree root. */ /* NB: In order to avoid complexities of passing parameters to the * multi-nested tree, tree operations are not nested, instead: * * - In the case of fetch, we load the subtree root stored in the * parent tree leaf. * - In the case of update/insert, we call dbtree_update() which may * create the root for the subtree, or just return it if it's already * there. */
在 Go 语言中,结构体就像是类的一种简化形式,那么面向对象程序员可能会问:类的方法在哪里呢?在 Go 中有一个概念,它和方法有着同样的名字,并且大体上意思相同:Go 方法是作用在接收者(receiver)上的一个函数,接收者是某种类型的变量。因此方法是一种特殊类型的函数。一个类型加上它的方法等价于面向对象中的一个类。一个重要的区别是:在 Go 中,类型的代码和绑定在它上面的方法的代码可以不放置在一起,它们可以存在在不同的源文件,唯一的要求是:它们必须是同一个包的。
areaIntf = sq1 // Is Square the type of areaIntf? if t, ok := areaIntf.(*Square); ok { fmt.Printf("The type of areaIntf is: %T\n", t) } if u, ok := areaIntf.(*Circle); ok { fmt.Printf("The type of areaIntf is: %T\n", u) } else { fmt.Println("areaIntf does not contain a variable of type Circle") } }
funcclassifier(items ...interface{}) { for i, x := range items { switch x.(type) { casebool: fmt.Printf("Param #%d is a bool\n", i) casefloat64: fmt.Printf("Param #%d is a float64\n", i) caseint, int64: fmt.Printf("Param #%d is a int\n", i) casenil: fmt.Printf("Param #%d is a nil\n", i) casestring: fmt.Printf("Param #%d is a string\n", i) default: fmt.Printf("Param #%d is unknown\n", i) } } }
var dataSlice []myType = FuncReturnSlice() var interfaceSlice []interface{} = make([]interface{}, len(dataSlice)) for i, d := range dataSlice { interfaceSlice[i] = d }
funcmain() { var x float64 = 3.4 v := reflect.ValueOf(x) // setting a value: // v.SetFloat(3.1415) // Error: will panic: reflect.Value.SetFloat using unaddressable value fmt.Println("settability of v:", v.CanSet()) v = reflect.ValueOf(&x) // Note: take the address of x. fmt.Println("type of v:", v.Type()) fmt.Println("settability of v:", v.CanSet()) v = v.Elem() fmt.Println("The Elem of v is: ", v) fmt.Println("settability of v:", v.CanSet()) v.SetFloat(3.1415) // this works! fmt.Println(v.Interface()) fmt.Println(v) } //输出: settability of v: false type of v: *float64 settability of v: false The Elem of v is: <float64 Value> settability of v: true 3.1415 <float64 Value>
反射结构体:
``NumField()方法返回结构体内的字段数量
通过for循环用索引取得每个字段的值Field(i)
用签名在结构体上的方法,例如,使用索引 n 来调用:Method(n).Call(nil)
接口与动态类型:
Go 中的接口跟 Java/C# 类似:都是必须提供一个指定方法集的实现。但是更加灵活通用:任何提供了接口方法实现代码的类型都隐式地实现了该接口,而不用显式地声明。
Cargo is the Rust package manager. It is a tool that allows Rust packages to declare their various dependencies and ensure that you’ll always get a repeatable build.
Creating a new package
cargo new hello_world --bin
cargo build
cargo run
cargo build --release
Working on an existing package
git clone
cargo build: fetch dependencies and build them
Package layout
Cargo.toml and Cargo.lock are stored in the root of your package
src for source code
src/lib.rs for default library files
Other executables can be placed in src/bin/.
Benchmarks go in the benches directory.
Examples go in the examples directory.
Integration tests go in the tests directory.
toml and lock
Cargo.toml is about describing your dependencies in a broad sense, and is written by you.
Cargo.lock contains exact information about your dependencies. It is maintained by Cargo and should not be manually edited.
cargo update will update dependencites to newest version
Tests
Command cargo test
run unit tests in /src/tests dir
run integration-style tests in /tests dir
Cargo Reference
Specifying Dependencies
specifying dependencites from crates.io:default choice
Caret requirements:an update is allowed if the new version number does not modify the lefct-most non-zero digit in the major,minor,patch grouping
Tilde requirements:specify a minimal version with some ability to update(not specified part can be modified)
Wildcard requirements:allow for any version where the wildcard is positioned
comparison requirements: allow manually specifying a version range or an exiact version to depend on
multiple requirements:eperated with comma
specifying dependencies from other registries
specifying depemdencies from git repositories
specifying path dependencies
Mutiple locations
Platform specified dependencies
Cargo commands
General Commands
cargo
cargo help
cargo version
Build Commands
cargo bench:execute benchmarks of a package
cargo build:Compile the current package
cargo check: check a local package and all of its dependencies for errors
cargo clean:remove artifacts feom the target directory that Cargo has generated in the past
cargo doc:build the documentation for the local pakage and all dependencies.the output is placed in target/doc
cargo fetch:fetch dependencies of a pakage from the network
cargo fix:automatically fix lint warnings reported by rustc
cargo run:run binary or exaple if local package
cargo rustc:copile the current package
cargo rustdoc:build a pakage’s documentation
cargo test: execute unit and integration test of package
Manifest Commands
cargo generate-lockfile:create cargo.lock file for the curren package or workspace.if already exists, rebuild the lastest avaliable version of every package
cargo locate-project: print a JSON object to stdout with the full path to the Cargo.toml manifest
cargo metadata:output JSON to stdout containning info about the memebers and resolved deoendencies of the current package,–format-version is recommended
cargo pkgid: print out the fully qualified package ID specifier for a package or dependency in the curren workspace
cargo tree:display a tree of dependencies to the terminal
cargo update:update dependencies as recorded in the local lock file
cargo vendor:vendor all crates.io and git dependencies for a project into the specified directory at <path>. After this command completes the vendor directory specified by <path> will contain all remote sources from dependencies specified.
cargo verify-project:parse the local manifest and check it’s validity
Package commands
cargo init:create a new cargo manifest in the current directory.
cargo install:This command manages Cargo’s local set of installed binary crates. Only packages which have executable [[bin]] or [[example]] targets can be installed, and all executables are installed into the installation root’s bin folder.
cargo new:create a new cargo package in the given directory.
cargo search:this performs a textual search for crates on cargo repository.The matching crates will be displayed along with their descriptioin in TOML format suitable for copying into a Cargo.html manifest.
cargo uninstall:by default all binaries are removed for a crate but –bin and –example flags can be used to only remove particular binaries.
Publishing Commands
cargo login:This command will save the API token to disk so that commands that require authentication, such as cargo-publish(1), will be automatically authenticated. The token is saved in $CARGO_HOME/credentials.toml. CARGO_HOME defaults to .cargo in your home directory.
cargo owner:This command will modify the owners for a crate on the registry. Owners of a crate can upload new versions and yank old versions. Non-team owners can also modify the set of owners, so take care!
cargo package:This command will create a distributable, compressed .crate file with the source code of the package in the current directory. The resulting file will be stored in the target/package directory.
cargo publish:This command will create a distributable, compressed .crate file with the source code of the package in the current directory and upload it to a registry.
cargo yank:The yank command removes a previously published crate’s version from the server’s index. This command does not delete any data, and the crate will still be available for download via the registry’s download link.
fnmain() { let a = [1, 2, 3, 4, 5]; let a: [i32; 5] = [1, 2, 3, 4, 5]; let a = [3; 5]// size 5 with initial value 3 }
visited by index
Functions
Coding stype: snake case. All letters are lowercase and underscores separate words
start with fn
Function Parameters
type of each parameter must be declared
multiple parameters separated with commas
Function bodies contain statements and expressions
Expressions do not include ending semicolons, if have, expression turns to statement,which will not return a value
Functions with return values
Declare return vlaue types after a ->
the return value of the function is synonymous with the value of the final expression in the block of the body of a function.
Comments
//
Control Flow
If Expressions(if-else if-else)
Loop(loop)
1 2 3 4 5
fn main() { loop { println!("again!"); } }
break & continue can use lable to apply to the labled loop
you can add the calue you want returned after the break expression
conditional loop with while
For loop:for element in collection
Understanding Ownership
What is ownership?
Memory is managed through a system of ownership with a set of rules that the compiler checks at compile time.
Stack and Heap
stack for known, fixed size data at compile time
heap is less organized, freee space must be serached
hense stack is more efficiency
when code calls a function ,value passed into function and variables get pushed onto the stack , when the function is over, those values get poped off the stack
heap is controlled by ownership
Ownership rules
Each value in Rust has variable that’s called its owner
There can only be one owner at a time
When the owner goes out of scope,the value will be dropped
Variable Scope
When varianle comes into scope, it is valid
it remains valid until it goes out of scope
The String type
string is immutable but String not
Memory and Allocation
Ways Variables and Data interact:Move
primitive types allocated on stack
Reference allocated on stack
Data allocated on heap
For ptimitive types: s1 = s2 means copy on stack
For non-primitive types: s1 = s2 means referece copied on stack and data on heap did not do anything
Ways Varianles and Data interact:Clone
if we do want to deeply copy the heap data of the String, not just the stack data, we can use a common method called clone
Stack-Only data:copy
Types such as integers that have a known size at compile time are strored entirely on the stack ,so copies of the actual values are quick to make.
if a type implements the copy trait, an doler variable is still usable after assignment.
Ownership and functions
The semantics for passing a value to a function are similar to those for assigning a value to a variable.Passing a variable to a funtion will move or Copy.For ptimitive types, after funciton calling, variable is still valid, but for other(e.g. String) types, calling function means ownership moving ,which meams s will be invalid after function call.
Return values and scope
returning values can also transfer ownership
The ownership of a variable follows the same pattern every time: assigning a vlaue to another variable moves it.When a variable that includes data on the heap goes out of scope,the value will be cleaned by drop unless the data has been moved to be owned by another variable.
References and Borrowing
reference allow you to refer to some value without taking ownership of it.
The &s1 syntax lets us create a reference that refers to the value of s1 but does not own it. Because it does not own it, the value it points to will not be dropped when the reference stops being used.
When functions have rederences as parameters intead of the actual values, we won’t need to return the values in order to give back ownership, because we never had ownership.We call the action of creating a reference borrowing.
Modifying something borrowed is not allowed, just as variables are immutable by default, so are references.
Mutable references have one big restiction:you can have only one mutable reference to a particular piece of data at a time.The restriction preventing multiple mutable references to the same data at the same time allows for mutation but in a very controlled fashion.Rust prevents data races even in compile time.Samelly, combining mutable and immutable references is also no permitted.(considered it is same as RW lock mechanism).Note that a reference’s scope starts from where it is introduced and continues through the last time that references is used.
Dangling References
In languages with pointers, it’s easy to erroneously create a dangling pointer, a pointer that references a location in memory that may have been given to someone else, by freeing some memory while preserving a pointer to that memory. In Rust, by contrast, the compiler guarantees that references will never be dangling references: if you have a reference to some data, the compiler will ensure that the data will not go out of scope before the reference to the data does.
The rules of References
At any given time, you can have either one mutable references or any number of immutable references.
Referebces must always be valid.
The Slice Type
A String Slice is a reference to part of a String.
We can create slices using a range within brackets by specifying [starting_index..ending_index], where starting_index is the first position in the slice and ending_index is one more than the last position in the slice.
if starting_index omitted, which means start from zero, if ending_index omitted, which means end to last byte, if all ommited, which means reference the total string
The type that signifies “string slice” is written as &str
The compiler will ensure the references into the String remain valid.
String literals are slices:let s = "Hello, World", the type of s here is &s, it is a slice poting to that specified piont of the binary, This is also why string literals are immutable, &str is an immutable reference.
Using structs to structure related data
Defining an instantiating structs
Structs are similar to tuples, but unlike with tuple, you will name each piece of data so it is clear what the values mean.Structs are more flexible than tuples:you don’t have to rely on the order of the data so specify or access the value of an instance.
kv pairs visited(read or write) by dot.
Creating instances from other instances with struct update syntax
Using struct update syntax, we can achieve the same effect with less code, as shown in Listing 5-7. The syntax .. specifies that the remaining fields not explicitly set should have the same value as the fields in the given instance.
fnmain() { let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, };
let user2 = User { email: String::from("another@example.com"), ..user1 }; }
Using Tuple Structs Without Named Fields to Create Different Types
1
structColor(i32, i32, i32);
Unit-Like Structs Without Any Fields
1 2 3 4 5
fnmain() { structAlwaysEqual;
let subject = AlwaysEqual; }
Method Syntax
Method are similar to functions, but methods are different from functions in that they’re defined within the context of a struct and their first parameter is always self, which represents the instance of the stuct the method is being called on.
Where is the -> Operator?
Rust has a featured called automatic referencing and dereferencing.
Associated Functions
All functions defined within an impl block are called associaterd functions because they’re associated with the type name after the impl
Associated functions that aren’t methods are often used for constructors that will return a new instance of the struct.
impl Message { fncall(&self) { // method body would be defined here } }
let m = Message::Write(String::from("hello")); m.call(); }
The OptionEnum and it’s advantages over Null values
When we have Somevalue,we know that a value is present and the value is held within the Some
When we have a Nonevalue,in some sense, it means the same thing as null
In other words, you have to convert an Option<T> to a T before you can perform T operations with it.Generally, this helps catch one of the most common issues with null: assuming that something isn’t null when it actually is.
match expression is a control flow construct that does just this when used with enums.
The match control flow operator
1 2 3 4 5 6 7 8 9 10 11
fnmain() { fnplus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let five = Some(5); let six = plus_one(five); let none = plus_one(None); }
Matches Are Exhaustive
Matches in Rust are exhaustive, we must exhaust every last possibility in order for the code to be valid.Especially inthe case of Option<T>, when Rust prevent us from forgetting to explicitly handle None case.
Catch-all Patterns and the _ Placeholder
for match default arm, we can use other and _to handle this.
The if letsyntax lets you combine if and let into a less verbose way to handle values that match one pattern while ignoring the rest.
In other words, you can think of if let as syntax sugar for a match that runs code when the value matches one pattern and then ignores all other values.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
fn main() { let config_max = Some(3u8); match config_max { Some(max) => println!("The maximum is configured to be {}", max), _ => (), } } fn main() { let config_max = Some(3u8); if let Some(max) = config_max { println!("The maximum is configured to be {}", max); } }
let row = vec![ SpreadsheetCell::Int(3), SpreadsheetCell::Text(String::from("blue")), SpreadsheetCell::Float(10.12), ]; }
Storing UTF-8 Encoded Text with Strings
Create a new String
let data = "initial contents".to_string()
let s = String::from("initial contents")
Update a String
s.push_str("bar")
s.push('l')
1 2 3 4
let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2; // + use fn add(self, s: &str) -> String {
use format! Macro is recomended
1 2 3 4 5
let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe");
let s = format!("{}-{}-{}", s1, s2, s3);
format! macro works in the same way as ptintln! but instead of printing the output to the screen,it returns a String with the contents. The code generated by the format! macro uses references so that this call doesn’t take ownership of any of its parameters.
Index into Strings
index to a String is not valid.
Slice Strings
s[start..end]
Methods for Iterating Over Strings
for c in "abcde".chars()
for b in "abcde".bytes()
Storing keys with associated values in hash maps
Creating a hash map
1 2 3 4
use std::collections::HashMap; letmut scores = HashMap::new(); scores.inert(String::from("Blue"), 10); scores.indert(String::from("Yellow"),50);
Another way with two vec
1 2 3 4
use std::collections::HashMap; let teams = vec![String::from("Blue"), String::from("Yellow")]; let initial_scores = vec![10, 50]; letmut scores: HashMap<_, _> = teams.into_iter().zip(initial_scores.into_iter()).collect();
HashMaps and ownership
For types that implement the copy trait, the values are copied into the hashmap.For owned values like String, the values will be moved and the hashmao will be the owner of those values.
Accessing values in a hashmap
let team_name = String::from("Blue")
let score = scores.get(&team_name)
1 2 3 4 5 6
use std:collections::Hashmap; letmut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); for(key, value) int &scores { println!("{}:{}",key, value); }
The or_insert method on Entry is defined to return a mutable reference to the value for the corresponding Entry key if that key exists, and if not ,inserts the parameter as the new value for this key and returns a mutable reference to the new value.
Updating a value based on the old value
1 2 3 4 5 6
let text = "hello world wonderful world"; letmut map = HashMap::new(); for word in text,split_whitespcae() { let count = map.entry(word).or_intsert(0); *count += 1; }
The or_insert method actually returns a mutable reference(&mut v) to the value for this key.
Error Handling
Unrecoverable Erros with panic!
Recoverable Errors with Result
Resuit Enum
1 2 3 4 5 6 7 8
use std::fs::File; fnmain(){ let f = File::open("hello.txt"); let f = match f { OK(file) => file, Err(error) => panic!("Problem opening the file: {:?}", error), }; }
Mathcing on different errors
1 2 3 4 5 6 7 8 9 10 11
fnmain() { let f = File::open("hello.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("hello.txt").unwrap_or_else(|error| { panic!("Problem creating the file: {:?}", error); }) } else { panic!("Problem opening the file: {:?}", error); } }); }
Shortcuts for panic on error:unwrap and expect
unwrap is a shortcut method that is implemented just like the matchexpression.if the Result value is Ok variant,unwrap will return the value inside the Ok.If the Result is the Err variant,unwrap will call the panic!macro for us.
let f = File::open("hello.txt").unwrap()
We use expect in the same way as unwrap: to return the file handle or call the panic! macro. The error message used by expect in its call to panic! will be the parameter that we pass to expect, rather than the default panic! message that unwrap uses.
let f = File::open("hello.txt").expect("Failed to open")
Propagating Errors
A shortcut for prapagating errors:? operator
1 2 3 4 5 6
fnread_username_from_file() -> Result<String, io::Error> { letmut f = File::open("hello.txt")?; letmut s = String::new(); f.read_to_string(&mut s)?; Ok(s) }
If the value of the Result is an OK,tge value insideOk will get returned from this expression, and the program will continue.if the value is an Err, the Err will be returned from the whole function as if we had used return keyword so the error value gets propagated to the calling code.
The ? operator can be used in functions that have type of Result.
To panic! Or Not To panic!
So how do you decide when you should call panic! and when you should return Result? When code panics, there’s no way to recover. You could call panic! for any error situation, whether there’s a possible way to recover or not, but then you’re making the decision on behalf of the code calling your code that a situation is unrecoverable. When you choose to return a Result value, you give the calling code options rather than making the decision for it. The calling code could choose to attempt to recover in a way that’s appropriate for its situation, or it could decide that an Err value in this case is unrecoverable, so it can call panic! and turn your recoverable error into an unrecoverable one. Therefore, returning Result is a good default choice when you’re defining a function that might fail.
Generic Types, Traits, and LifeTImes
Generic Data Types
In Function Definitions
Before we use a para,eter in the body of the function, we have to declare the parameter name in the signature so the compiller knows what that name means.
A trait tells the Rust compiler about functionality a particular type has and can share with other types. We can use traits to define shared behavior in an abstract way. We can use trait bounds to specify that a generic type can be any type that has certain behavior.
We have implemented the Summary trait on the NewsArticle and Tweet types.We can define a notify function that calls the summarize method on its item parameter,which is of some type that implements the Summary trait.
Attention, you can only use impl Trait if you‘re returning a sigle type.
Using Trait Bounds to Conditionally Implement Methods
We can also conditinally implement a trait for any type that implements another trait.Implementations of a trait on any type that satisfies the trait bounds are called blanket implementations.
Validating references with lifetimes
Preventing dangling references with lifetimes
The Borrow checker
Generic Lifetimes in functions
Lifetime Annotation Syntax
Lifetime Annotations in function signatures
1 2 3 4 5 6 7
for longest<’a>(x: &'astr,y: &'astr) -> &'astr{ if x,len() > y.len() { x } else { y } }
The function signature now tells Rust that for some lifetime 'a, the function takes two parameters, both of which are string slices that live at least as long as lifetime 'a. The function signature also tells Rust that the string slice returned from the function will live at least as long as lifetime 'a. In practice, it means that the lifetime of the reference returned by the longest function is the same as the smaller of the lifetimes of the references passed in. These constraints are what we want Rust to enforce. Remember, when we specify the lifetime parameters in this function signature, we’re not changing the lifetimes of any values passed in or returned. Rather, we’re specifying that the borrow checker should reject any values that don’t adhere to these constraints. Note that the longestfunction doesn’t need to know exactly how long x and y will live, only that some scope can be substituted for 'a that will satisfy this signature.
Thinking in terms of lifetimes
Lifetime annotations in struct dedinitions
We have only defined structs to hold owned types.It is possible for structs to hold references, but in that case we would need to add a lifetime annotation on every reference in the struct’s definition.
1 2 3 4 5 6 7 8 9 10 11
structImportantExcerpt<'a> { part: &'astr, }
fnmain() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); let i = ImportantExcerpt { part: first_sentence, }; }
This annotation means an instance of ImportantExcerpt can not outlive the reference it holds in its part field.
Lifetime Elision
Lifetimes on function or method parameters are called input lifetimes, and lifetimes on return values are called output lifetimes.
Three rules for lifetime:
Each parameter that is a reference gets its own lifetime parameter
If there is exactly one input lifetime parameter, that lifetime is assigned to all output lifetime parameters
There are multiple input lifetime parameters, but one of them is &selft or &mut self because this is a method, the lifetime of self is assigned to all output lifetime parameters.
Lifetime Annotations in Method Definitions
Lifetime names for struct fields always need to be declared after the impl keyword and then used after the struct’s name, because those lifetimes are part of the struct’s type
fnmain() { let string1 = String::from("abcd"); let string2 = "xyz";
let result = longest_with_an_announcement( string1.as_str(), string2, "Today is someone's birthday!", ); println!("The longest string is {}", result); }
use std::fmt::Display;
fnlongest_with_an_announcement<'a, T>( x: &'astr, y: &'astr, ann: T, ) -> &'astr where T: Display, { println!("Announcement! {}", ann); if x.len() > y.len() { x } else { y } }
Writing Automated Tests
How to Write Tests?
Checking resutls with the assert! Macro
We give the !assert Marco an argument that avaluates to a Boolean,if the value is true, assert! does nothing an the test passes,if the value is false, the assert! Macro calls the panic! macro.
Testing equality with the assert_eq! And assert_ne! marcos
Adding custom failure messages
Checking for panics with should_panic
To our test function, this attribute makes a test pass if the code inside the function panics, thet test will fial if the code inside the function doesn’t panic.
The #[cfg(test)] annotation on the tests module tells Rust to compile and run the test code only when you run cargo test, not when you run cargo build.
Function Language features:iterators and closures
Closures:aninymous functions that can capture their environment
To define a closure, we start with a pair of vertical pipes|,after the parameters,we place curly brackets that hold the body of the closure,which is optinal if the closure body is a sigle expression.
Closures don’t require you to annotate the types of the parameters or the return value like functions do.The compiler is reliably able to infer the types if the paramaters and the return value, similar to how it’s able to infer types of most variables.
1 2 3 4
fnadd_one_v1(x: u32) -> u32 { x + 1 } let add_one_v2 = |x: u32| -> u32 { x + 1 }; let add_one_v3 = |x| { x + 1 }; let add_one_v4 = |x| x + 1 ;
Once user calling a closure, compiler refers the type of closure paramaters, and types are then locked into the closure,and we get a type error if we try to use a difference type with the same closure.
Cloures have an additional capability that functions don’t have: they can capture their environment and access variables from the scope in which they’re defined.
1 2 3 4 5 6 7 8 9 10 11
fnmain() { let x = 4;
fnequal_to_x(z: i32) -> bool { z == x }
let y = 4;
assert!(equal_to_x(y)); }
Closures can capture value from their environment in three ways,which directly map to the three ways a function can take a parameter:taking ownership, borrowing mutably, and borrowing immutably.These are encoded in three Fn traits as follows:
FnOnce:consumes the variables it captures from its enclosing scope, known as the closure’s environment.To consume the captured variables, the closure must take ownership of these variables and move them into the closure when it is defined.The once part of the name represents the fact that the closure can’t take ownership of the same variables more than once, so it can be called only once.
FnMut:can change the environment because it mutably borrows values.
Fn:borrows values from the environment immutably
When you create a closure, Rust infers which trait to use based on how the closure uses the values from the environment. All closures implement FnOnce because they can all be called at least once. Closures that don’t move the captured variables also implement FnMut, and closures that don’t need mutable access to the captured variables also implement Fn. In Listing 13-12, the equal_to_xclosure borrows x immutably (so equal_to_x has the Fn trait) because the body of the closure only needs to read the value in x.
If you want to force the closure to take ownership of the values it uses in the environment, you can use the move keyword before the parameter list. This technique is mostly useful when passing a closure to a new thread to move the data so it’s owned by the new thread.
1 2 3 4 5 6 7 8 9 10 11 12
fnmain() { let x = vec![1, 2, 3];
let equal_to_x = move |z| z == x;
println!("can't use x here: {:?}", x); // move this line, the code can be compiled
let y = vec![1, 2, 3];
assert!(equal_to_x(y)); }
Processing a series of items with iterators
Iterators are lazy
The Iterator trait an next method
1 2 3 4 5 6 7
pubtraitIterator { typeItem;
fnnext(&mutself) -> Option<Self::Item>;
// methods with default implementations elided }
The valuies we get from the calls to next are immutable references to the values in the vector.The iter method produces an iterator over immutable references.If we want to create an iterator that takes ownership of vector and returns owned values, we can call into_iter instead of iter.Similarly, if we want to iterate over mutable references, we can call iter_mut instead of iter.
Methods that consume the iterator
1 2 3 4 5
fniterator_sum() { let v1 = vec![1,2,3]; let v1_iter = v1.iter(); let total:i32 = v1.iter.sum(); }
Methods that produce other iterators
1 2
let v1: Vec<i32> = vec![1,2,3] let v2: Vec<_> = v1.iter().map(|x| x+1).collect();
We use collect method to consume the iterator because iterators are lazy, we collect the results of iterating over the iterator that’s returned from the call to map into a vector.
Using closures that capture their environment
filter iterator adaptor:The filter method on an iterator takes a closure that takes each item from the iterator and returns a boolean.If the closure returns true, the value will be included in the iterator produced by filter, if the closure returns false, the value won’t be included in the resulting iterator.
Closures and iterators are Rust features inspired by functional programming language ideas. They contribute to Rust’s capability to clearly express high-level ideas at low-level performance. The implementations of closures and iterators are such that runtime performance is not affected. This is part of Rust’s goal to strive to provide zero-cost abstractions.
More about Cargo and Crates.io (Not covered)
Smart Pointers
In Rust, which uses the concept of ownership and borrowing, an additional difference between references and smart pointers is that the reference are pointers that only borrow data; in contrast, in many cases, smart pointers own the data they point to.
Using Box to point to data on the heap
Boxes allow you to store data on the heap rather than the stack, what remains on the stack is the pointer to the heap data.
Enabling recursive types with boxes
Treating smart pointers like regular references with the Deref trait
Implementing the Deref trait allows you to customize the behavior of the dereference operator, *(as opposed to the multiplication or glob operator). By implementing Deref in such a way that a smart pointer can be treated like a regular reference, you can write code that operates on references and use that code with smart pointers too.
Without the Deref trait, the compiler can only dereference & references.The deref method gives the compiller the ability to take value of any type that implements Deref and call the deref method to get a & reference that it knows how to dereference.
Implicit deref coercions with functions and methods
Deref coercion is a convenience that Rust performs on arguments to functions and methods. Deref coercion works only on types that implement the Deref trait. Deref coercion converts such a type into a reference to another type. For example, deref coercion can convert &String to &str because String implements the Deref trait such that it returns &str. Deref coercion happens automatically when we pass a reference to a particular type’s value as an argument to a function or method that doesn’t match the parameter type in the function or method definition. A sequence of calls to the deref method converts the type we provided into the type the parameter needs.
Deref coercion was added to Rust so that programmers writing function and method calls don’t need to add as many explicit references and dereferences with & and *. The deref coercion feature also lets us write more code that can work for either references or smart pointers.
fnmain() { let m = MyBox::new(String::from("Rust")); hello(&m); }
with rust deref coercions, the code is equal to
1 2 3 4
fnmain() { let m = MyBox::new(String::from("Rust")); hello(&(*m)[..]); }
How deref coercion interacts with mutability
rust does deref coercion when it finds types and trait implementions in three cases:
From &T to &U when T: Deref<Target=U>
From &mut T to &mut U when T: DerefMut<Target=U>
From &mut T to &U when T: Deref<Target=U>
Running code on cleanup with the drop trait
The second trait important to the smart pointer pattern is Drop, which lets you customize what happens when a value is about to go out of scope. You can provide an implementation for the Droptrait on any type, and the code you specify can be used to release resources like files or network connections. We’re introducing Drop in the context of smart pointers because the functionality of the Drop trait is almost always used when implementing a smart pointer. For example, when a Box<T> is dropped it will deallocate the space on the heap that the box points to.
Programmer do not have to free memory in code when finishing using an instance of a data type.In rust, when a value goes out of scope,the compiler will insert ‘free memory’ code automatically.
Most of time, programmers do not have to drop memory of one instance before the scope ending, if have to, rust provides a method std::mem::drop to do this.
Rc, the reference counted smart pointer
To enable multiple ownership, Rust has a type called Rc<T>, which is an abbreviation for reference counting. The Rc<T> type keeps track of the number of references to a value to determine whether or not the value is still in use. If there are zero references to a value, the value can be cleaned up without any references becoming invalid.
We use the Rc<T> type when we want to allocate some data on the heap for multiple parts of our program to read and we can’t determine at compile time which part will finish using the data last. If we knew which part would finish last, we could just make that part the data’s owner, and the normal ownership rules enforced at compile time would take effect.
1 2 3 4 5 6 7 8 9 10 11 12 13
enumList { Cons(i32, Rc<List>), Nil, }
use crate::List::{Cons, Nil}; use std::rc::Rc;
fnmain() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
acceptor只处理收到的的prepare或者propose中epoch>= last promised epoch的消息
For each prepare or propose message received, the acceptor’s last promised epoch is set to the epoch received. This is after Property 6 has been satisfied.
For each prepare message received, the acceptor replies with promise. This is after Properties 6 & 7 have been satisfied.
For each propose message received, the acceptor replies with accept after updating its last accepted proposal. This is after Properties 6 & 7 have been satisfied.
Last promised epoch and last accepted proposal are persistent and only updated by Properties 7 & 9
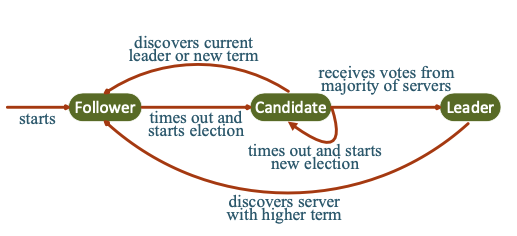
选举流程:follower increments current term(term += 1) 并且转换为candidate状态,vote for self并且并行的发送requestVote RPC给集群中的其他server
candidate保持状态直到:
赢得选举
其他server赢得选举
一段时间过去了没有胜出者
candidate赢得选举的条件:在 same term的条件下获取集群内大部分server的votes。一个server只能为一个candidate vote,first-come-first-serverd。一旦赢得选举则向其他的节点发送heartbeat to prevent new election
If server a‘s term smaller than b’s, a change it’s term to b’s
candidate of leader founds larger term, trun itself to follower
if server recieved stale term request , reject it
Log replication
流程
command come
leader append command to it’s log
Sent log to other servers to replicate the entry
recieved most servers reply, leader apply this comand to it’s state machine
return result to client
(if followers crash or run slowlly, or network issues, leader send rpc infinitely until all followers store all log)
log structure
state machine command
term number
to detect inconsistencies between logs
integer index
to identify its position in the log
commited log entries
when ont entry has replicated it on a majority of servers
leader includs highest index it knows to be commietted int appedEntries RPCs so other followers learns that and then commite that entry to its state machine
how to handle inconsistencies?
by forcing the follower’s logs to duplicate it’s own(follower overrited)
leader 存储每个follower的nextIndex array,此array初始值为last one of leader index + 1,然后向follower发送AppendEntries RPC用于指针探测,如果探测失败则以1步距回退,直到找到一个agree point。(Leader Append-Only确保了leader不会删除或者覆盖他自己的log)
Write:more heavy beacause all nodes need to participate, but compution only need once because head compute the value and other nodes only need to do once write.

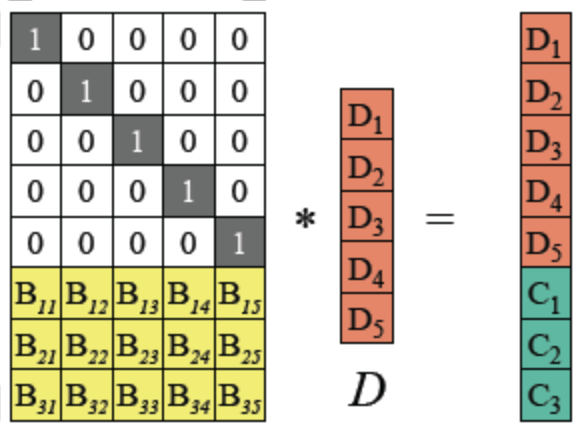
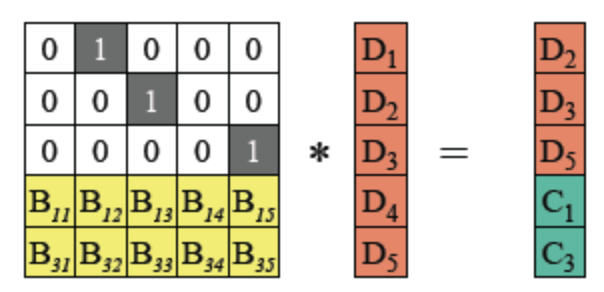
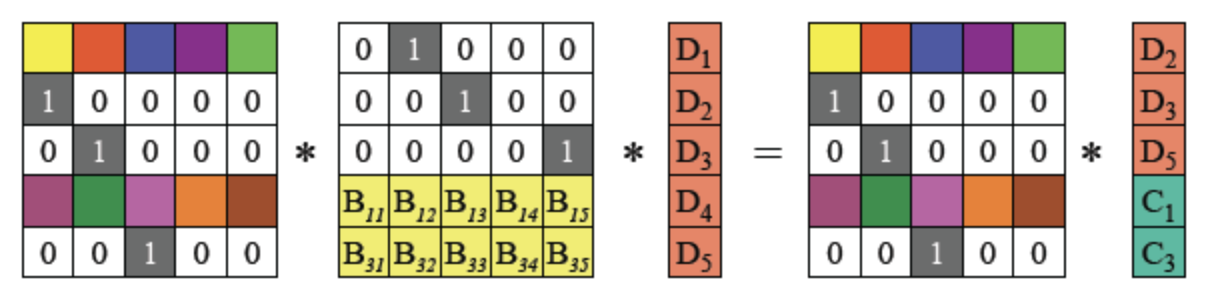
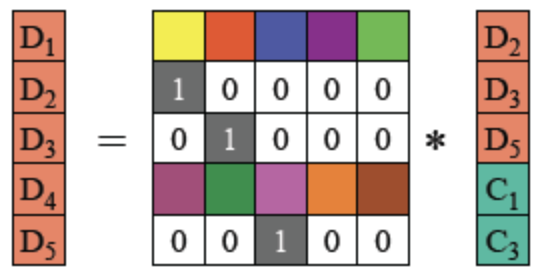
 阶单位矩阵,是一个n×n
阶单位矩阵,是一个n×n 的
的 且InB=B
且InB=B (任何矩阵与单位矩阵相乘都等于本身)
(任何矩阵与单位矩阵相乘都等于本身)